Downloading all photos at once from marathonfoto
They didn't give me a "download all" button so I had to make my own.
They didn’t give me a “download all” button so I had to make my own
I ran in an event which supplied (free) race photos to the participants, which was distrbuted via marathonfoto.com. Great!
Using the site, you can click on individual photos and download them at full resolution. They have a “Download or Print” button, but it only tries to sell you photo prints. They don’t have a “download all” button.
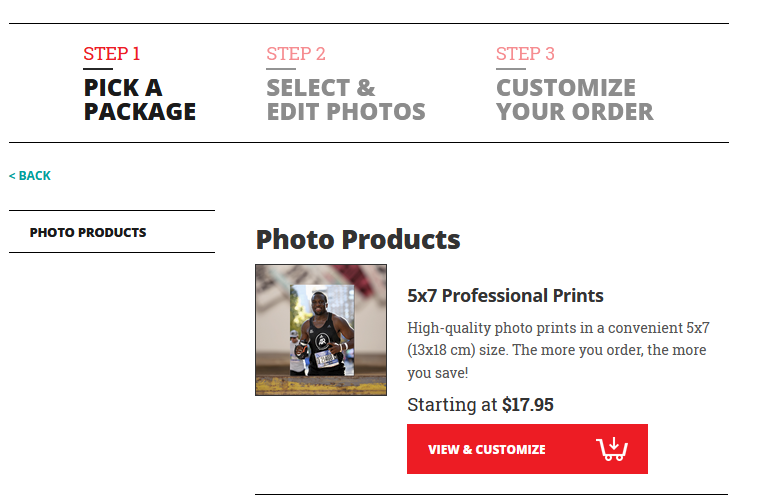
I’m not bypassing any DRM, the images were free, I just didn’t want to click “Download” 28 times
The solution
I didn’t check to see if I could reach their API, so my solution scrapes the web page for a list of the image URLs. I ran this in my browser’s devtools console:
$('.gal-image__sponsored-link').toArray().map(function (x) { return x.getAttribute('data-sponsored-image-url')})
Once I had a list of images, I saved it to a file called urls.txt, line separated. Then I ran this python script (this was faster than xargs and curl, because of the filenames). I copied the cookie value from my browser dev tools as well:
import requests
# apparently this isn't necessary
# headers_val = {'Cookie': 'LastKnownCredentials=< Copy this from dev tools >'}
images = []
with open('urls.txt', 'rt') as f:
images = f.readlines()
assert images is not None
img = 0
for i in images:
i = i.strip() # cr lf endings wasted a half hour of my time
filename = f'file{img:02}.jpg'
print('url', i)
# no authentication was actually necessary here
r = requests.get(i, None, allow_redirects=True, stream=True)
r.raise_for_status()
with open(filename, 'wb') as f:
f.write(r.content)
img += 1
Some notes from along the way
I started by tracking the link from my email. I didn’t have to create an account, and it knew my number, and so the link in my inbox contained just my pictures.
The first link was behind some tracker redirect, which one of my browser extensions had flagged at first. It then redirects to:
https://www.marathonfoto.com/In?
RaceOID=<Race Occasion Id>
&LastName=<Last Name>
&BibNumber=<Bib Number>
&utm_source=<Tracking Source>
&utm_medium=email
&utm_campaign=<Email Campaign Name>
&_kx=<Tracking Id>
Then, redirects again to:
https://www.marathonfoto.com/Home/Search?
BibNumber=<Bib Number>
&OccasionRef=<Race Occasion Id>
&LastName=<Last Name>
&utm_source=<Tracking Source>
&utm_medium=email
&utm_campaign=<Email Campaign Name>
&_kx=<Tracking Id>
And then to here, where it gives you a PIN.
https://www.marathonfoto.com/Proofs?
PIN=<6 digits, A-Z 0-9>
&LastName=<Last Name>
&utm_source=<Tracking Source>
&utm_medium=email
&utm_campaign=<Email Campaign Name>
&_kx=<Tracking Id>
A cookie is saved with the value LastKnownCredentials=PIN=<PIN>&LastName=<LastName>. I actually found out after writing my script that the cookie or header isn’t actually required to download the file.
What’s weird to me is that if you know the RaceOID, LastName, and BibNumber, you can look up photos for anyone in the event. (Everything after is optional.) It’s fine because the event was in a public park, and this was probably in the paperwork, but I’m not sure if I want these all to be publicly indexable after I’ve downloaded them.
The full name and bib number of race participants are available to anyone that raced in the event, the results were all viewable from links on printed QR codes around the event. (On a separate website.)
I am not Matt, but I can view all of his pictures (removed personal details):
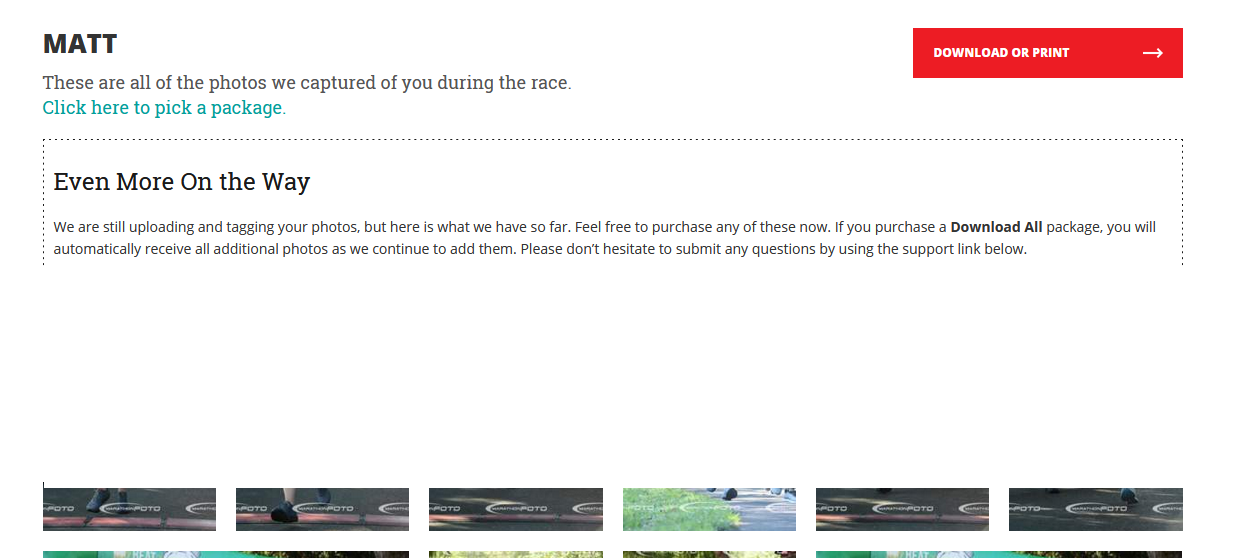
But upon closer inspection, this seems to be by design, the event website redirects to a search box which lets you search all photos by last name. Seems by design, but odd that they bother with the PIN number at all…
I think it would be nice if you could “claim” the photos that were emailed to you. I would prefer if I could specify that not anyone could download (and order prints of) my pictures during an event, after I’ve got to them first. I think this could be done with user-defined PINs, or PINs which are distributed separately, since they already have my email. Maybe this is how it’s done when the photos are behind a paywall?
Is that the right image?
I’ve tried to scrape other sites where the thumbnails are a lower quality version of the image, and the full image is elsewhere. They do the same with thumbnails here (and add a watermark).
Thankfully, the /Proofs page organizes them all neatly with data attributes:
<a
href="javascript:void(0);"
data-frame-id="<Frame ID>"
data-occasion-ref="<Occasion Id>"
data-sponsored-image-url="https://www.marathonfoto.com/Rendering/Sponsored?frameId=<Frame ID>&sponsoredImageId=<Sponsored Image ID>&customerRef=<PIN>"
data-sponsored-preview-url="https://www.marathonfoto.com/Rendering/SponsoredPreview?frameId=<Frame ID>&sponsoredImageId=<Sponsored Image ID>&customerRef=<PIN>"
data-sponsor-name="Enjoy your FREE PHOTOS"
class="gal-image__sponsored-link js-button-sponsored-images">
<div class="gal-image__sponsored">
<span>Free Download</span>
</div>
</a>
The thumbnail uses the data-sponsored-preview-url, but the full download
used the data-sponsored-image-url.
The images I downloaded all seem to look nice, and it was free. Cool.
Anyways
Could I just get a “download all” button next time?